

Introduction
This article is a high-level overview of Compado’s internal software to support our Paid-Search Teams in their operations.
In order to identify Purchase-Motivated Audiences in Search Engines, Compado is a heavy user of the Google and Bing ad networks. Our Paid Search Team operates hundreds of ad network accounts across many industries and countries.
The ad networks provide their own user interfaces which are sufficient for most tasks, including the ability to select and change many marketing entities (e.g. campaigns) at the same time. However, even this can be manual and error-prone, and furthermore, the ability to make the same change to many accounts simultaneously is limited.
Compado’s AdTech (Ad Technology) system came into being in March 2021 with the aim of using the Google and Bing APIs to automate some of the manual work done by the Paid Search marketing team, and, through automation, to provide functionality which would be impractical with the existing tools. The ad network APIs had already long been in use by the company for work such as conversion uploads and performance reports, so the AdTech system was able to build on prior knowledge in this area.
Architecture
The AdTech system has a simple architecture, as shown below:
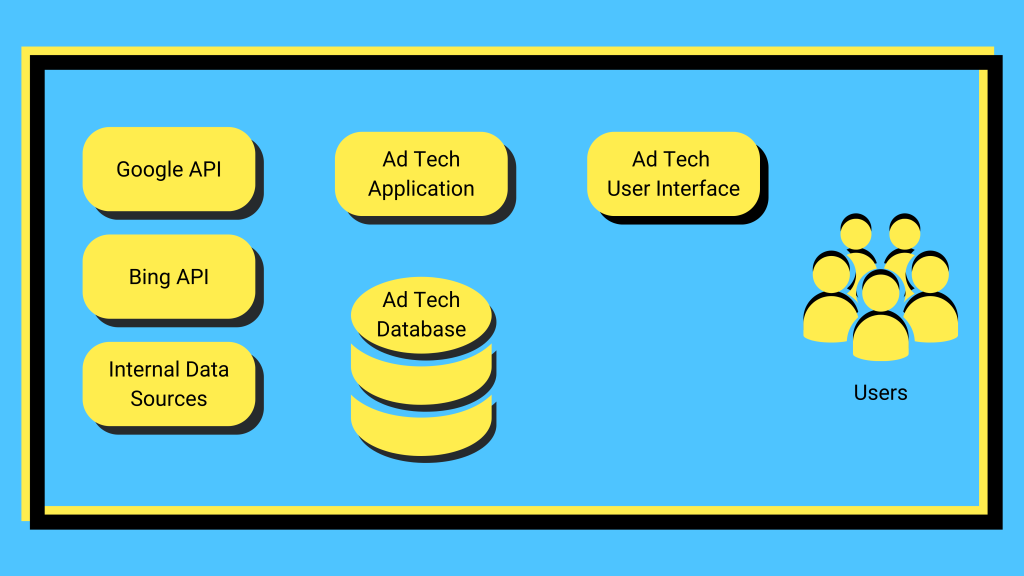
The system has three parts:
Application
The application is the heart of the system and has three main concerns:
- Manage data from external sources, particularly the ad network APIs
- Retrieve and manipulate marketing entity data from the ad network APIs
- Make changes to marketing entities via the ad network APIs
- Retrieve and change data from other sources
- Manage reading and writing to the database
- Provide an internal API to the system’s user interface
The data retrieved from the ad networks by AdTech does not include performance data, since this is handled by our Data team and made available to other teams via our data warehouse.
The application creates two executables:
- A command-line application (CLI) for task scheduling, such as hourly monitoring of account status and daily downloading of entity data
- An HTTP server (SRV) which provides a JSON REST API to the user interface
The application directory structure shows how both executables share the majority of their code:
- CLI – task scheduling code
- SRV – HTTP server code, including related concerns such as authentication and JSON marshaling
- internal – AdTech business logic which can be called by either CLI or SRV
- stores – database access code
- pkg – packages, i.e. libraries
Database
The bulk of the data in the database is marketing entity data synced from the ad networks. There is also data synced from internal sources such the data warehouse, and a small amount of data entered by users.
The schemas of the database show how it is organized:
- bing – entities downloaded from Bing API
- google – entities downloaded from Google API
- core – tables which combine common Bing and Google entities and add internal metadata, such as the assignment of ad network accounts to specific countries
- common – data which can be reused in any application, such as countries and currencies
The “core” schema is possible because there is a great deal of overlap in the structure of the Google and Bing marketing entities, so a table that combines them contains few network-specific columns.
User interface
The user interface is a SPA (single page application) which consumes the internal API provided by the application. It has three sections:
- A list of tools which allow specialized functionality requested by the Paid Search team, such as
- “Ad Customizer”, which allows the user to change the text of ads in many ad groups simultaneously
- “Keyword Collector”, which presents new keyword ideas to the user and allows him to add them to selected campaigns
- A list of admin pages, such as:
- a page to manage negative keywords which need to be synced to ad network accounts
- a list of assignments of users to certain industry and country combinations. This is used to ensure that notifications affecting a certain industry and country reach the right person
All three system components are deployed to AWS.
Technologies
The following technologies are used by the AdTech system:
Go
The application is written in Go. This was a slightly unusual choice for an application that needs to access the Google and Bing APIs, since it is lacking an SDK for both! However, Go makes up for this by being strong in data handling due to its type system and compile-time checks, and is also well-known for its utility in API creation.
We have also found that its facility for process parallelization is a good match for operating on many search engine accounts simultaneously.
PostgreSQL
The database is PostgreSQL, managed by AWS RDS. This choice was made simply to match the preference and experience of the developers. Since the application is so data-intensive, we make extensive use of database features such as checks, constraints, views and materialized views.
Vue JS with Vuetify
The user interface is written in Vue JS, and uses the Vuetify material design component library. This gives the UI a Google-like appearance, which the users appreciate due to its familiarity, since they spend a lot of time using Google tools.
Further points of interest
Here are some additional details regarding the AdTech system which may be of interest to the reader.
Layered ad network API access
As noted above, there are no Go SDKs for the ad network APIs, therefore we write our own client code.
The ad network APIs are constrained by a maximum number of entities per request, but since we have many accounts containing millions of entities, our requests would regularly exceed these limits. For this reason, we created two API access layers for each ad network:
- An inner layer, whose function names and structures mirror those of the API documentation exactly, making it easy to understand. These functions respect the maximum number of entities per request for each endpoint.
- An outer layer, which is called by the application. These functions are named according to business needs and wrap the inner layer functions, adding loops where needed to manage the maximum entity constraints.
No nullable columns
Due to the tricky errors that can result from using NULLs, we decided that we will not store NULL values in the database and added the corresponding constraint to all columns. This works well, with one exception: where a timestamp has a valid empty value, such as a “completed_at” column in a tasks table. There is no proper empty value for a timestamp, so in these cases, we created a boolean column such as “is_completed” and associated it with the timestamp in the application.
Syncing external data, rather than delete/insert cycle
Since there is a lot of data-crunching relating to ad network entities, it makes sense to download this data first, then crunch it in the database, rather than making continuous API calls. A large chunk of the application is therefore concerned with syncing ad network entities with their corresponding database tables in a sensible and performant manner.
A common way of syncing external data is simply to remove the existing data and then insert the new data. This guarantees that the new data is correct. However, it also breaks consistency in the database and does not provide information about which records have actually changed. With millions of records of data, it also creates an unnecessary load on the database. So we didn’t want to do this.
Instead, each external entity synced into the database uses a method which determines the new records, the changed records and deleted records and only makes the changes needed. This is done by comparing the latest external API data to the existing database data using a unique comparison key, which in most cases is provided by the external data (such as a unique Google/Bing ID per campaign).
The result is a sync process that is smooth and performant, and application logs that only show changes, making the sync process easy to monitor.
Custom soft delete solution
The usual soft delete (i.e. reversible record delete) solution is a “deleted_at” or “is_deleted” column in the affected table. However, these columns interfere with the use of key and unique constraints in the database, and so on balance, we didn’t want to do this.
In the AdTech system, there are luckily only a handful of tables containing user-entered data, and only a few of these needed a soft delete solution. However, these tables have a hierarchical relationship, so deletes in table A should cascade to deletes in table B, but records in table B can also be deleted independently.
We developed a custom method for this:
- we mirror the structure of the affected tables into “table A deleted” and “table B deleted”
- we add “deleted_at” and “deleted_by” columns to both, and also “is_cascaded” to “table B deleted”
- if a record in table A is deleted in the user interface, it is moved via application code to “table A deleted”, and the same application code handles the cascaded deletes to table B, while setting “is_cascaded” to true
- the user interface shows a list of deleted table A records by simply selecting from “table A deleted”. If this delete is reversed by the user, the application handles the record’s move back into table A, and also the corresponding reverse of the deletes in table B using the “is_cascaded” column
- independent deletes to table B work the same way, except “is_cascaded” is set to false
For data changes, no such complexity is needed. We simply use a trigger to get the old and new values, calculate which columns have changed and write the difference to a log table.